데이터베이스 확장(feat.Sharding & Partitioning)
데이터베이스 확장
하나의 데이터베이스로 다룰 수 없을 만큼 데이터가 많아지게 되면 데이터베이스 읽기/쓰기 성능이 감소하게 되므로 데이터베이스 확장에 대한 고려를 해야 한다. 이 글에서는 고려할 수 있는 방안으로 샤딩(Sharding)과 파티셔닝(Partitioning)을 소개해본다.
샤딩(Sharding)이란?
샤딩은 동일한 스키마를 가지고 있는 여러 대의 데이터베이스 서버들에 데이터를 작은 단위로 나누어 분산 저장하는 기법으로 쪼개지는 단위를 샤드(shard)라 한다. 데이터의 수평 분할 방식이라고도 하는데, 수평 분할(Horizontal Partitioning)이란 스키마(Schema)가 같은 데이터를 두 개 이상의 테이블에 나누어 저장하는 것을 말한다. 예를 들어 같은 주민 데이터를 처리하기 위해 스키마가 같은 ‘서현동주민 테이블’과 ‘정자동주민 테이블’을 사용하는 것을 말한다. 인덱스의 크기를 줄이고 작업 동시성을 늘리기 위한 것으로 보통 하나의 데이터베이스 안에서 이루어지나 샤딩의 경우 물리적으로 다른 데이터베이스에 데이터를 수평 분할 방식으로 분산 저장하고 조회하는 방법이다.
고려사항
위의 예시와 같이 주민 테이블이 여러 DB에 있을 때 ‘서현동주민 테이블’은 A DB에 ‘정자동주민 테이블’은 B DB에 저장하는 것이기 때문에, 여러 샤드에 걸친 데이터를 조인(Join)하는 것에 제약이 있을 수 있다. 또한, 하나의 데이터베이스에 집중적으로 데이터가 몰리면 Hotspot이 되어 성능이 느려질 수 있다.
레인지샤딩(Range Sharding)
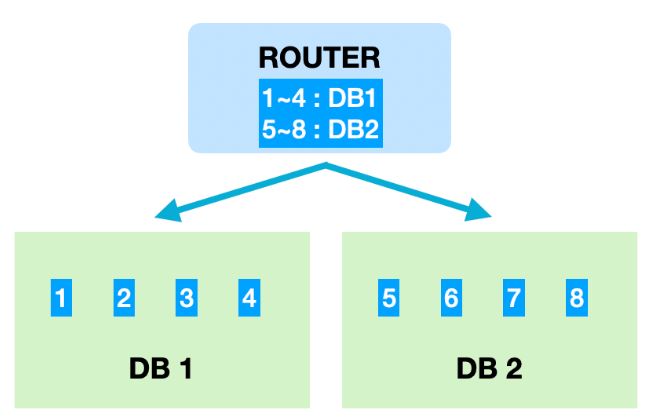 이미지 출처 레인지샤딩은 PK의 범위를 기준으로 DB를 특정하는 방식이다. 예를 들어 PK가 1~4번까지는 1번 샤드에, 5~ 부터는 2번 샤드에 저장할 수 있다. 해시 샤딩(Hash Sharding)에 비해 데이터베이스 증설 작업에 큰 리소스가 소요되지 않기 때문에 급격히 증가할 수 있는 성격의 데이터는 레인지샤딩 방식이 좋은 선택지가 될 수 있다.
이미지 출처 레인지샤딩은 PK의 범위를 기준으로 DB를 특정하는 방식이다. 예를 들어 PK가 1~4번까지는 1번 샤드에, 5~ 부터는 2번 샤드에 저장할 수 있다. 해시 샤딩(Hash Sharding)에 비해 데이터베이스 증설 작업에 큰 리소스가 소요되지 않기 때문에 급격히 증가할 수 있는 성격의 데이터는 레인지샤딩 방식이 좋은 선택지가 될 수 있다.
하지만 특정 데이터베이스에만 부하가 몰릴 수 있다는 단점이 있는데, 예를 들어 페이스북 게시물을 레인지샤딩했다고 가정했을 때 대부분의 트래픽은 최근에 작성한 게시물에서 발생할 것이다. 즉 마지막 레인지에 해당하는 샤드에서만 부하가 몰릴 것이기 때문에 부하 분산을 위해 부하가 몰리는 DB는 재샤딩하고, 부하가 적은 DB는 다시 통합하여 유지비용을 아끼도록 관리해야 한다.
- 장점: DB 개수가 변경됨에 따른 데이터의 재정렬이 발생하지 않는다.
- 단점: 특정 DB에 데이터가 몰릴 수 있다.
모듈러샤딩(Modular Sharding)
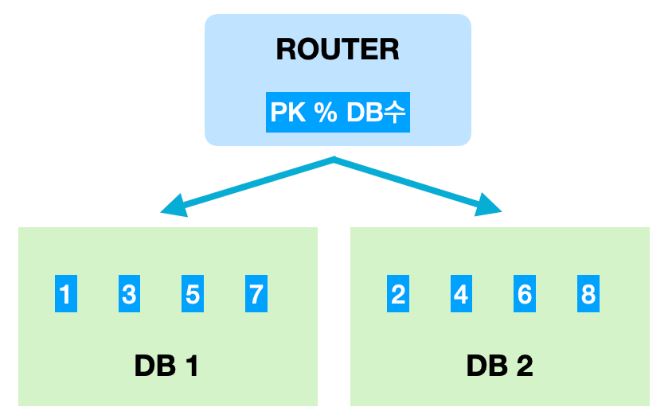 이미지 출처 모듈러샤딩은 해시 샤딩(Hash Sharding)의 한 종류로, 나머지 연산을 사용한 샤딩 방식이다. PK를 모듈러 연산한 결과로 DB를 특정하는 방식으로, 총 데이터베이스 수가 정해져 있을 때 즉, 데이터량이 일정 수준에서 유지될 것으로 예상되는 데이터 성격을 가진 곳에 적용할 때 유용하다.
이미지 출처 모듈러샤딩은 해시 샤딩(Hash Sharding)의 한 종류로, 나머지 연산을 사용한 샤딩 방식이다. PK를 모듈러 연산한 결과로 DB를 특정하는 방식으로, 총 데이터베이스 수가 정해져 있을 때 즉, 데이터량이 일정 수준에서 유지될 것으로 예상되는 데이터 성격을 가진 곳에 적용할 때 유용하다.
- 장점: 레인지샤딩(Range Sharding)에 비해 데이터가 균일하게 분산되어 트래픽을 안정적으로 소화하면서도 DB리소스를 최대한 활용 가능하다.
- 단점: DB의 개수가 변경되면 이미 적재된 데이터의 재정렬이 필요하다.
파티셔닝(Partitioning)
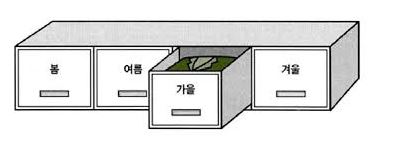 이미지 출처 파티셔닝은 하나의 큰 테이블을 여러 테이블로 분할하는 방식이다. 파티션 테이블은 논리적으로는 하나의 테이블이지만 물리적으로는 여러 개의 파티션으로 나뉘어 저장되고, 사용자는 마치 하나의 테이블에 접근하는 것과 같이 사용할 수 있다.
이미지 출처 파티셔닝은 하나의 큰 테이블을 여러 테이블로 분할하는 방식이다. 파티션 테이블은 논리적으로는 하나의 테이블이지만 물리적으로는 여러 개의 파티션으로 나뉘어 저장되고, 사용자는 마치 하나의 테이블에 접근하는 것과 같이 사용할 수 있다.
이를 가능하게 해주는 것이 파티션 테이블의 Pruning 이라는 기능인데, 특정 데이터를 조회할 때 해당 데이터가 속해 있는 세그먼트만 빠르게 조회할 수 있다.
파티션 테이블로 구성하기 좋은 테이블은 로그 테이블인데, 로그의 특성 상 몇 달만 지나도 크게 쓸모가 없어지는 데이터들이 많기 때문에 일, 월, 분기 단위로 파티셔닝한다면 필요한 로그를 조회하는 속도를 빠르게 만들 수 있고, 불필요한 데이터는 해당 파티션만 제거함으로써 효율적으로 데이터를 관리할 수 있다.
- 장점: 데이터 액세스 범위를 줄여 성능을 향상하고 테이블의 파티션 단위로 디스크의 I/O를 분산해 부하를 감소할 수 있다. 특정 DML과 쿼리의 성능을 향상시키고, 주로 대용량 데이터 쓰기 작업에서 효율적이다. 많은 INSERT가 있는 OLTP 시스템에서 INSERT 작업을 작은 단위인 파티션으로 분산시켜 경합을 줄인다.
- 단점: 파티션의 기준이 되는 것이 컬럼의 일부일 때, 일부를 기준으로 파티셔닝을 할 수 없기 때문에 이에 해당하는 오버헤드 컬럼이 있어야한다. 또한, Insert 속도가 느려질 수 있고 Join에 대한 비용이 증가한다.
참고
NHN의 안과 밖: Sharding Platform DB분산처리를 위한 sharding [DB] 파티션 테이블(Partition Table)이란 무엇인가?